# Introduction
Introduction to Neo4J for MySQL developers.
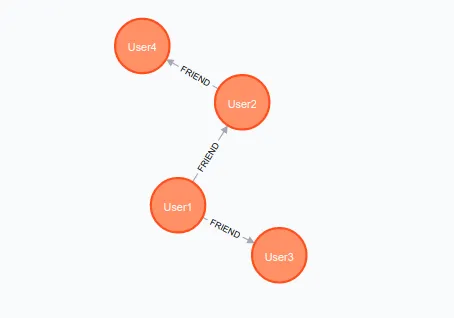
Neo4j is a graph database that stores data as nodes and relationships, focusing on the connections between data points. It's excellent for analyzing complex networks, like social graphs, recommendation engines, or fraud detection, because it can efficiently traverse these connections.
Regarding **Neo4j** and its relation to the CAP theorem, it's essential to understand that Neo4j is primarily designed as a highly consistent **(C) and partition-tolerant (P) system.**
**Single Instance (Standalone)**
* It is ideal for development, testing, or small-scale deployments.
* Install Neo4j directly on your server's operating system following the official documentation for your platform (Windows, Linux, macOS):
* This is the simplest method, but it lacks high availability and scalability.
**Clustering**
* Provides high availability and improved scalability compared to standalone or distributed setups.
* Involves more complex configuration and management of the cluster environment.
**HA/DR**
* It aims to minimize downtime and data loss in case of server failures or outages.
* This can be achieved in conjunction with clustering or through replication techniques:
* **Clustering:** When a server fails, the cluster manager automatically restarts the Neo4j instance on a healthy server, ensuring continuous service.
* **Replication:** Regularly copy your Neo4j database to a secondary server for disaster recovery. If the primary server becomes unavailable, you can switch to the secondary.
**Neo4J Aura (Cloud)**
Cloud-based service.
***
### **Use Cases:**
**Social Media**
**Fraud Detection in Real-time:** Banks and financial institutions are leveraging Neo4j to detect complex fraud patterns in real time, connecting the dots between transactions that would seem unrelated at first glance.
**Network and IT Operations:** Neo4j helps model networks and IT infrastructure to understand dependencies and impacts. This is super useful for predicting the effects of failures or planning upgrades.
**Personalized Recommendation:** Beyond the usual "users who bought this also bought that," Neo4j powers hyper-personalized recommendations by considering a user's entire interaction history and social connections.
**Knowledge Graph:** Beyond the usual Google-like stuff, companies use Neo4j for internal knowledge management, linking all kinds of data from emails to documents, making it searchable and discoverable in ways traditional databases can't.
***
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://gchandra.gitbook.io/big-data-and-tools-with-nosql/nosql/neo4j/introduction.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.
{kind=link}