# Data Mesh
**It's a conceptual operational framework or platform architecture - not a tool or software.**
It is built to address the complexities of managing data in large, distributed environments.
It shifts the traditional centralized approach of data management to a decentralized model.
The Data Mesh is a new approach based on a modern, distributed architecture for analytical data management.
The **decentralized technique** of data mesh distributes data ownership to domain-specific teams that manage, own, and serve the data as a product.
This concept is similar to **Micro Service architecture**.
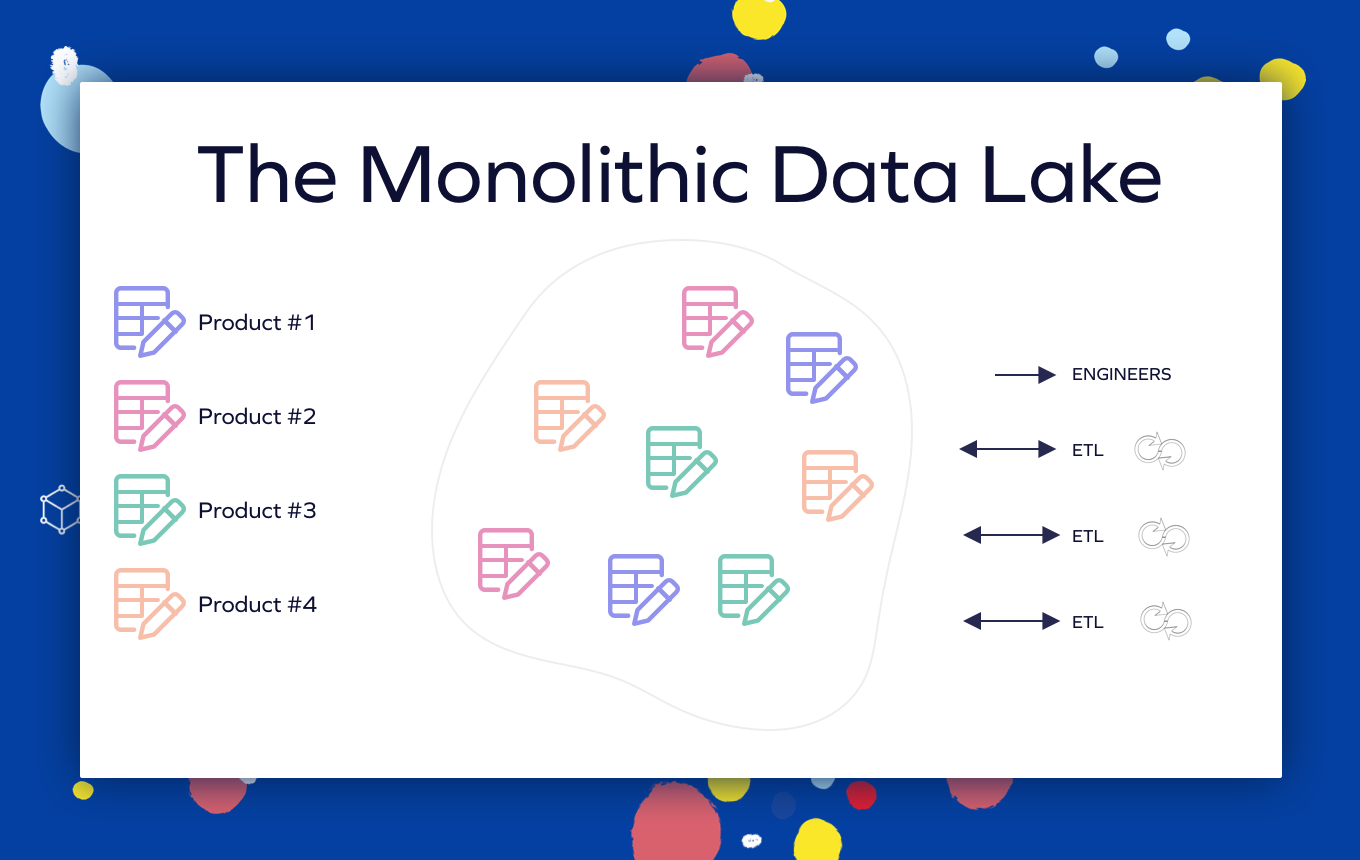
### **The Monolithic Data Lake**
There is no clear ownership and domain separation between the different assets. The ETL processes and engineer access to the platform are handled without a level of governance.
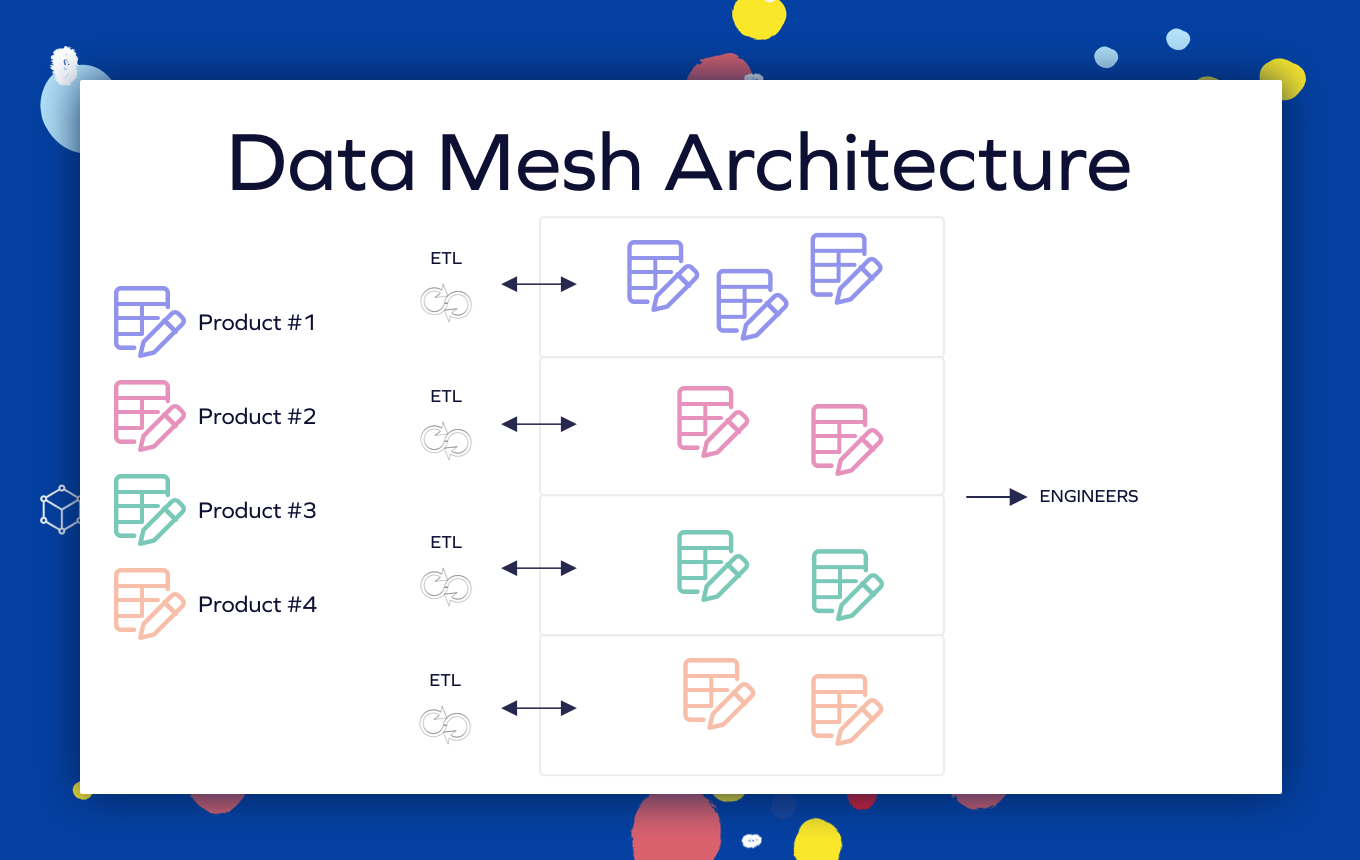
There is a notable separation between different domains’ data sources and pipelines. The engineers are given a domain-agnostic interface to the data platform.
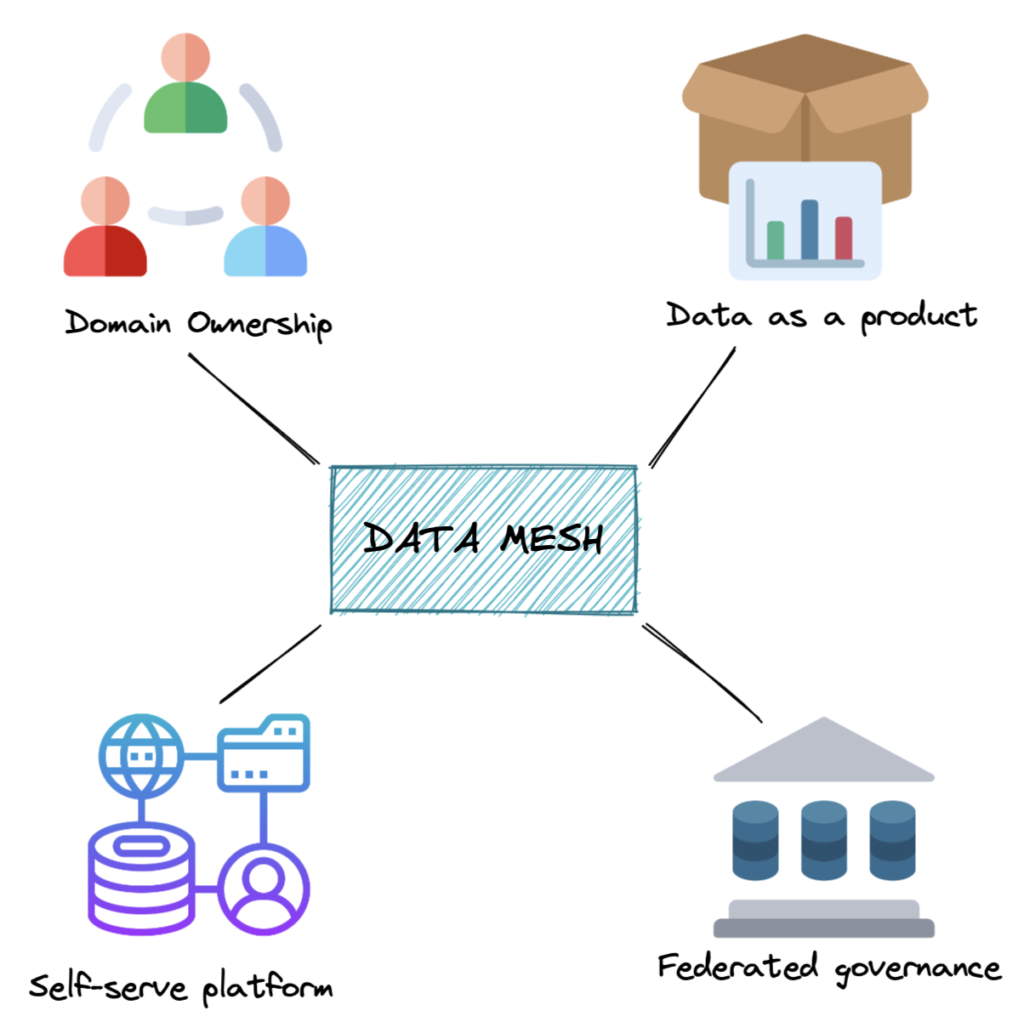
### 4 Pillars of Data Mesh (Core Principles)
**Domain ownership**: adopting a distributed architecture where domain teams - data producers - retain full responsibility for their data throughout its lifecycle, from capture through curation to analysis and reuse.
**Data as a product**: applying product management principles to the data analytics lifecycle, ensuring quality data is provided to data consumers who may be within and beyond the producer's domain.
**Self-service infrastructure platform**: taking a domain-agnostic approach to the data analytics lifecycle, using standard tools and methods to build, run, and maintain interoperable data products.
**Federated governance**: Governance practices and policies are applied consistently across the organization, but implementation details are delegated to domain teams. This allows for scalability and adaptability, ensuring data remains trustworthy, secure, and compliant.
### Data Products
Data products are an essential concept for data mesh. They are not meant to be datasets alone but data treated like a product:
They need to be
**Discoverable**
**Trustworthy**
**Self-describing**
**Addressable and interoperable.**
Besides data and metadata, they can contain code, dashboards, features, models, and other resources needed to create and maintain the data product.
### Benefits of Data Mesh in Data Management
**Agility and Scalability** - improving time-to-market and business domain agility.
**Flexibility and independence** - avoid becoming locked into one platform or data product.
**Faster access to critical data** - The self-serving model allows faster access.
**Transparency for cross-functional use across teams** - Due to decentralized data ownership, transparency is enabled.
### **Data Mesh Challenges**
**Cross-Domain Analytics** - It is difficult to collaborate between different domain teams.
**Consistent Data Standards** - ensuring data products created by domain teams meet global standards.
**Change in Data Management** - Every team has autonomy over the data products they develop; managing them and balancing global and local standards can be tricky.
**Skillsets:** Success requires a blend of technical and product management skills within domain teams to manage data products effectively.
**Technology Stack:** Selecting and integrating the right technologies to support a self-serve data infrastructure can be challenging.
**Slow to Adopt Process with Cost & Risk** - The number of roles in each domain increases (data engineer, analyst, scientist, product owner). An org needs to establish well-defined roles and responsibilities to avoid causing MESS.
**More reading**
{% embed url="" %}
{% embed url="" %}